-
UTF-8 UTF-16 인코딩에 대하여IT & Science 2021. 6. 21. 00:58
인코딩
문자 인코딩(영어: character encoding), 줄여서 인코딩은 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 말한다.
문자 인코딩 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
문자 인코딩 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 문자 인코딩(영어: character encoding), 줄여서 인코딩은 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 말한다. 넓은 의미의 컴퓨
ko.wikipedia.org
이러한 신호들을 인코딩으로 제작하고, 인코딩된 신호를 다시 원래 문자로 디코딩하여 복원해줄 필요가 있는데, 이를 위해서 미리 정해진 기준을 바탕으로 한 문자셋이 나오기 시작했다.
초기에는 ASCII나 EBCDIC와 같은 문자셋들이 나오다가 이후에 표준 문자셋인 UNICODE 가 생겼다.
ASCII
- 정의
미국정보교환표준부호(영어: American Standard Code for Information Interchange), 또는 줄여서 ASCII( /ˈæski/, 아스키)는 영문 알파벳을 사용하는 대표적인 문자 인코딩이다. 아스키는 컴퓨터와 통신 장비를 비롯한 문자를 사용하는 많은 장치에서 사용되며, 대부분의 문자 인코딩이 아스키에 기초를 두고 있다.
ASCII - 위키백과, 우리 모두의 백과사전 (wikipedia.org)아스키는 7비트로 구성된 인코딩으로 총 128개의 문자들로 이루어진다.
총 1바이트로 문자들을 표현할 수 있는 문제셋이며,
'A' 문자는 ASCII 코드로 나타내면 10진수로 65,
'@' 문자는 ASCII 코드로 나타내면 10진수로 64가 된다.

ASCII 코드표 UNICODE
유니코드(영어: Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이며, 유니코드 협회(Unicode Consortium)가 제정한다
유니코드 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
유니코드 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 유니의 음반에 대해서는 U;Nee Code 문서를 참고하십시오. 유니코드(영어: Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된
ko.wikipedia.org
기존의 1바이트인 ASCII 문자셋으로는 표현할 수 있는 문자들이 부족했기 때문에 더 많은 문자들을 담을 수 있는 문자셋이 필요해졌다.
또한 인터넷이 발달되면서 여러 각국의 언어들이 있었기 때문에 이를 표준화 시켜야 할 필요가 생기면서 UNICODE 문자셋이 생기게 되었다.
이중에 대표적인 인코딩 포멧이 바로 UTF-8과 UTF-16이다.
각국의 나라의 문자들을 아래 사진과 같이 정의되어있다.

사진을 보면 한글(3130-318F, AC00-D7AF) 문자 또한 존재함을 볼 수 있다 Unicode Character Ranges (jrgraphix.net)
Unicode Character Ranges
jrgraphix.net
UTF-8
- 정의
UTF-8은 유니코드를 위한 가변 길이
문자 인코딩 방식 중 하나로, 켄 톰프슨과 롭 파이크가 만들었다. UTF-8은 Universal Coded Character Set + Transformation Format – 8-bit 의 약자이다. 본래는 FSS-UTF (File System Safe UCS/Unicode Transformation Format)라는 이름으로 제안되었다.
UTF-8 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)특징으로는 영문을 표현할 때는 ASCII 문자셋과 동일하게 1바이트를 사용한다는 점이 있다.
이때 한글은 3바이트를 사용한다고 한다.
UTF-16
- 정의
UTF-16(16-bit Unicode Transformation Format)은 유니코드 문자 인코딩 방식의 하나이다. 주로 사용되는 기본 다국어 평면 (BMP, Basic multilingual plane)에 속하는 문자들은 그대로 16비트 값으로 인코딩이 되고 그 이상의 문자는 특별히 정해진 방식으로 32비트로 인코딩이 된다.
UTF-16 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)특징은 영문과 한글과 같이 기본 다국어 평면(BMP, Basic multilingual plane)에 속하는 문자들은 2바이트 값으로 인코딩이 된다는 점이다.
또한 다음과 같은 성질을 같는다.
- 1바이트로 표시된 문자의 최상위 비트는 0이다.
- 2바이트 이상으로 표시된 문자의 경우, 첫 바이트의 상위 비트들이 그 문자를 표시하는 데 필요한 바이트 수를 결정한다.
- 예를 들어 2바이트면 110xxxxx 10xxxxxx
3바이트 이상이면 1110xxxx 10xxxxxx 10xxxxxx 과 같이 표현한다.
- 예를 들어 2바이트면 110xxxxx 10xxxxxx
- 첫 바이트가 아닌 나머지 바이트들은 상위 2비트가 항상 10이다.
- 예를 들어 2바이트면 110xxxxx 10xxxxxx
3바이트 이상이면 1110xxxx 10xxxxxx 10xxxxxx 과 같이 표현한다.
- 예를 들어 2바이트면 110xxxxx 10xxxxxx
UTF-8과 UTF-16의 구조는 아래와 같다
코드 범위(십육진법) UTF-16BE 표현(이진법) UTF-8 표현(이진법) 설명 000000-00007F 00000000 0xxxxxxx 0xxxxxxx ASCII와 동일한 범위 000080-0007FF 00000xxx xxxxxxxx 110xxxxx 10xxxxxx 첫 바이트는 110 또는 1110으로 시작하고,
나머지 바이트들은 10으로 시작함000800-00FFFF xxxxxxxx xxxxxxxx 1110xxxx 10xxxxxx 10xxxxxx 010000-10FFFF 110110ZZ ZZxxxxxx 110111xx xxxxxxxx 11110zzz 10zzxxxx 10xxxxxx 10xxxxxx UTF-16 서러게이트 쌍 영역 (ZZZZ = zzzzz - 1).
UTF-8로 표시된 비트 패턴은 실제 코드 포인트와 동일하다.UTF-8 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
UTF-8 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. UTF-8은 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나로, 켄 톰프슨과 롭 파이크가 만들었다. UTF-8은 Universal Coded Character Set + Transformation Format – 8-bit 의
ko.wikipedia.org
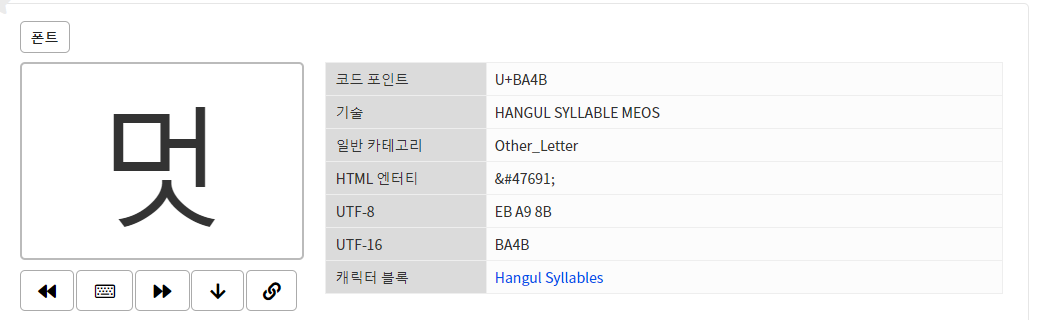
예를 들어서 "멋" 이라는 문자를 UTF-8로 변환해본다고 해보자
"멋"은 유니코드로 변환하게되면 U+BA4B가 된다.
이때 U+BA4B 는 000800 - 00FFFF 범위 안으로 있기 때문에 이진법으로 표현하게 되면
1110xxxx 10xxxxxx 10xxxxxx가 된다.
이제 이 틀에 맞추어서 해당 문자를 삽입하면 된다.
16진수 BA4B는 2진수로 바꾸게 되면 1011 1010 0100 1011 이다.

변환된 2진수 비트들을 틀에 맞추어서 순서대로 x위치에 넣게 되면,
11101011 10101001 10001011 이 된다.
결과적으로 해당 문자는 3바이트로 인코딩이 된다.
이를 16진수로 표시하게 되면 EB A9 8B 가 된다.
이러한 일련의 과정들을 확인해볼 수 있는 좋은 사이트가 있어서 링크를 남긴다.
유니 코드 문자 변환기 / 검색 : UTF-8, HTML 엔티티 등으로 변환하고 이스케이프 | RAKKOTOOLS🔧
유니 코드 문자 변환기 / 검색 : UTF-8, HTML 엔티티 등으로 변환하고 이스케이프 | RAKKOTOOLS🔧
UTF-8, UTF-16 등의 문자 코드와 HTML 엔터티와 같은 유니 코드 이스케이프 시퀀스를 변환하고 조회합니다.
ko.rakko.tools
'IT & Science' 카테고리의 다른 글
알아두면 유용한 것들 - 마크다운(Markdown) (0) 2020.10.11